This integration requires a UTMStack agent to work properly. Please, make sure you have installed it before you continue.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
1. Enable Filebeat module
Linux
cd /opt/utmstack-linux-agent/beats/filebeat/ && ./filebeat modules enable kafka
Windows
cd "C:\Program Files\UTMStack\UTMStack Agent\beats\filebeat\" && filebeat modules enable kafka
Configure the module configuration file according to the image below. You can find it in the path:
Linux
/opt/utmstack-linux-agent/beats/filebeat/modules.d/kafka.yml
Windows
C:\Program Files\UTMStack\UTMStack Agent\beats\filebeat\modules.d\kafka.yml
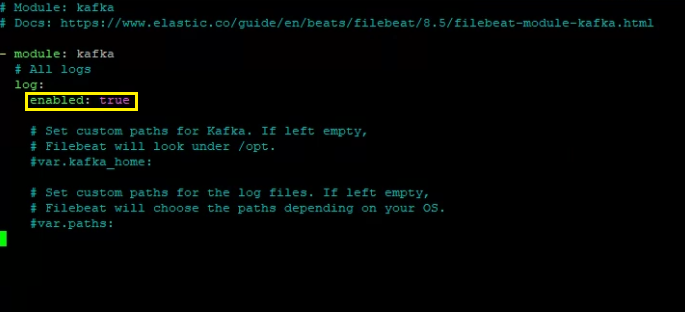
Important!! After a Filebeat module is enabled, the service needs to be restarted using the following command:
Linux
sudo systemctl restart UTMStackModulesLogsCollector
Windows
sc stop UTMStackModulesLogsCollector && timeout /t 5 && sc start UTMStackModulesLogsCollector
Depending on how you’ve installed Filebeat, you might see errors related to file ownership or permissions when you try to run Filebeat modules. See Config File Ownership and Permissions