New in v11: The architecture now features a manager-worker model with horizontal scalability, replacing the monolithic design of previous versions.
Core Architecture Components
Manager and Worker Nodes
UTMStack v11 uses a distributed architecture with two primary container types:Manager Node
Central coordination and management
- Web interface hosting
- User authentication and authorization
- Configuration management
- Alert orchestration
- API endpoints
- Database management
Worker Nodes
Distributed data processing
- Log ingestion and parsing
- Real-time correlation
- Threat detection
- Plugin execution
- Parallel processing
- Horizontal scalability
Key Architectural Features
EventProcessor Engine
EventProcessor Engine
Replaces Logstash with a custom-built, high-performance log processing engine developed by Threatwinds:
- Lower resource consumption
- Faster processing speeds
- Better memory management
- Native correlation capabilities
Modular Plugin System
Modular Plugin System
Official plugin architecture for extensibility:
- Independent feature modules
- Easy maintenance and updates
- Community contributions support
- Hot-swappable components
Horizontal Scaling
Horizontal Scaling
Add worker nodes to scale processing capacity:
- Linear performance scaling
- No single point of failure
- Load distribution across workers
- Automatic failover support
Deployment Models
UTMStack v11 supports multiple deployment models to meet different organizational needs:1. Single Node Deployment (Standalone)
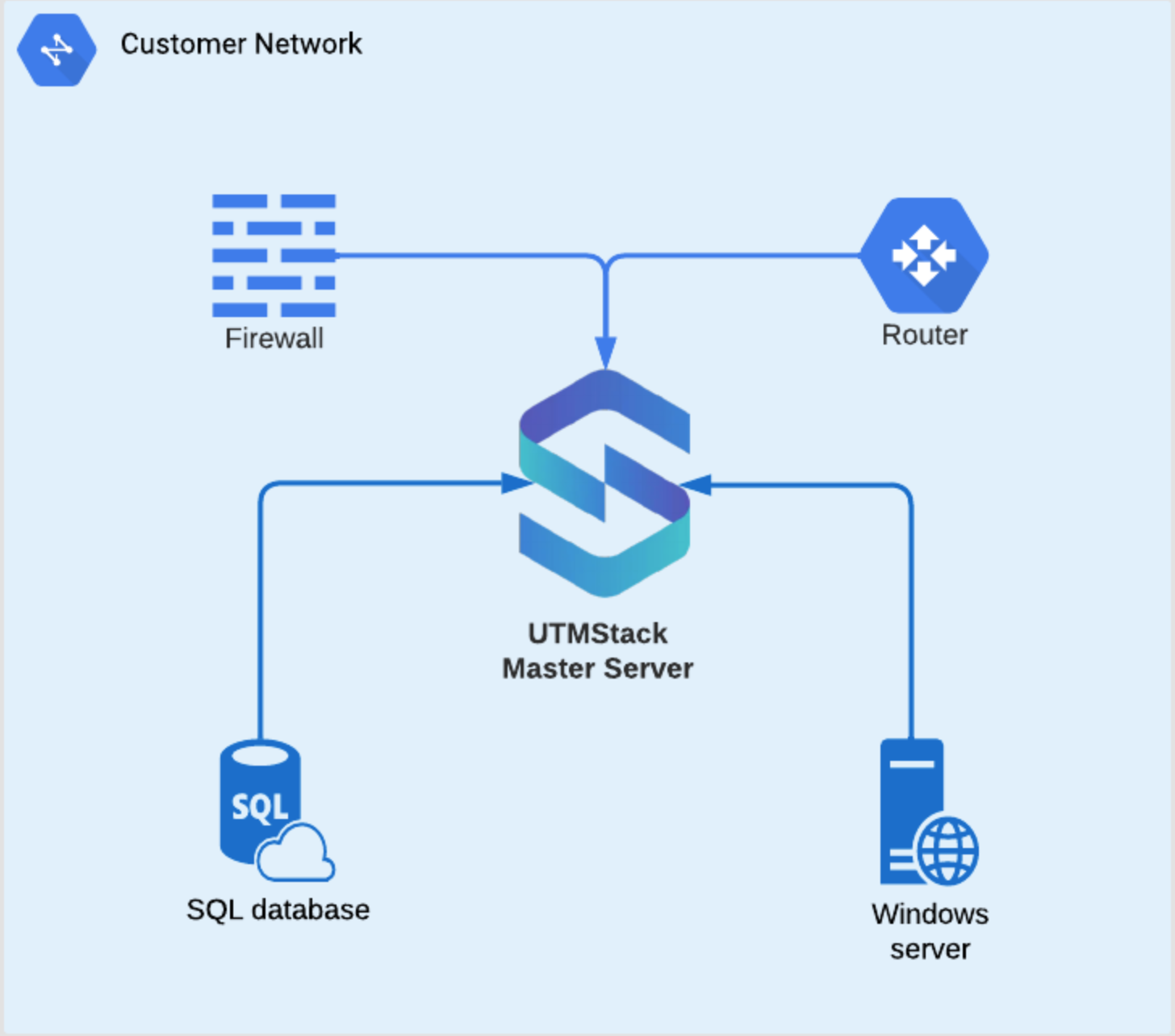
- Complete data control and isolation
- Simplified management
- Lower infrastructure costs
- Suitable for on-premises or cloud deployment
- Full SIEM/XDR capabilities
- All-in-one installation
- Direct log collection from devices
- Local data storage
- No external dependencies
- Enhanced security through data isolation
2. Multi-Node Deployment (Manager + Workers)
- One manager node for coordination
- Multiple worker nodes for data processing
- Horizontal scalability
- High availability options
- Load distribution
- Scalable architecture
- Add workers as needed
- Parallel log processing
- Better resource utilization
- Handles large data volumes efficiently
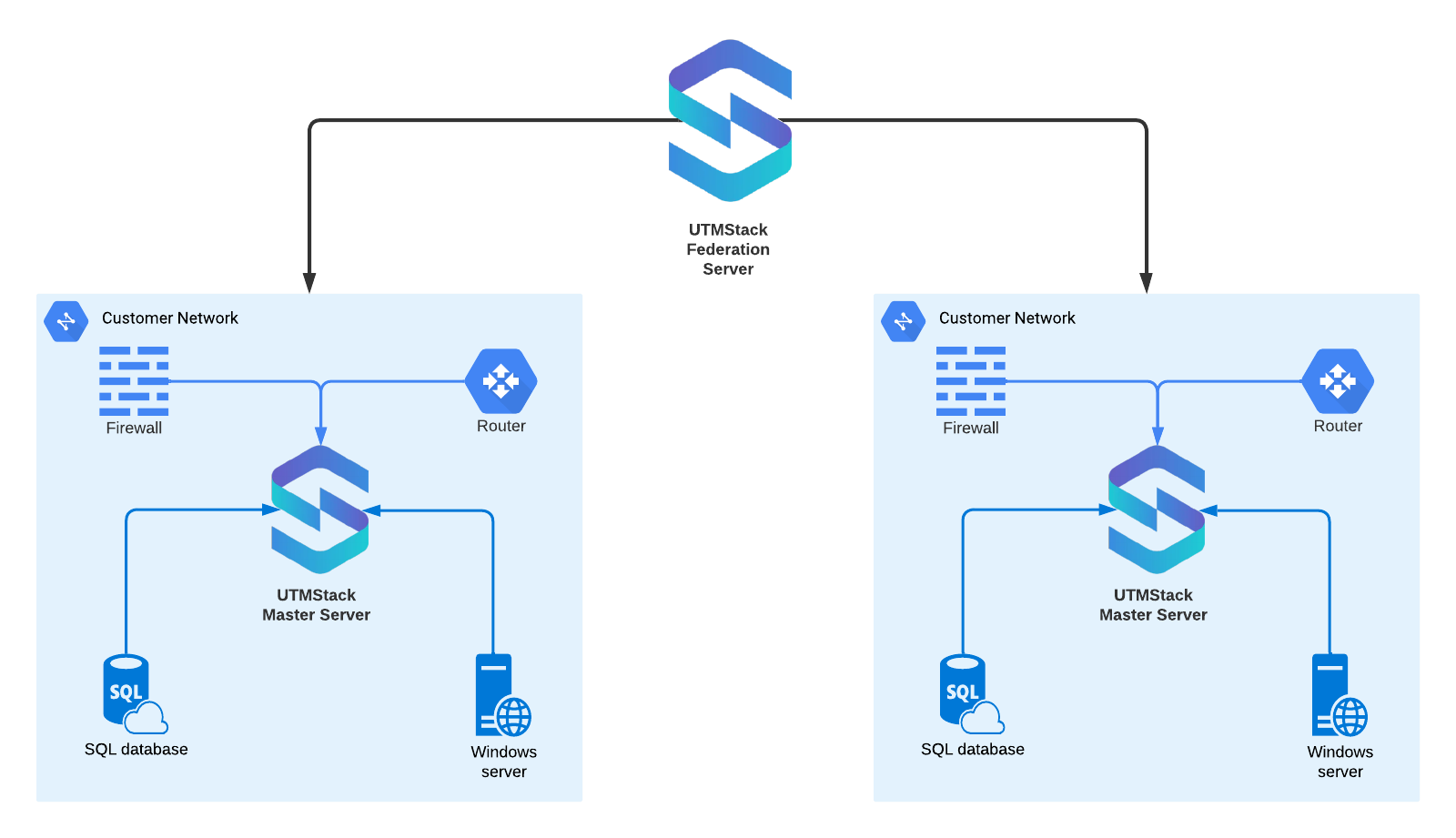
3. Federated Deployment (MSP Model)
- Separate UTMStack installation per customer
- Central federation server for unified monitoring
- Multi-tenant architecture
- Centralized alerting and reporting
- Customer data isolation
- One instance per customer network
- Central monitoring dashboard
- Unified alert management
- Efficient multi-customer oversight
- Scalable MSP operations
4. SaaS Deployment (Fully Managed)
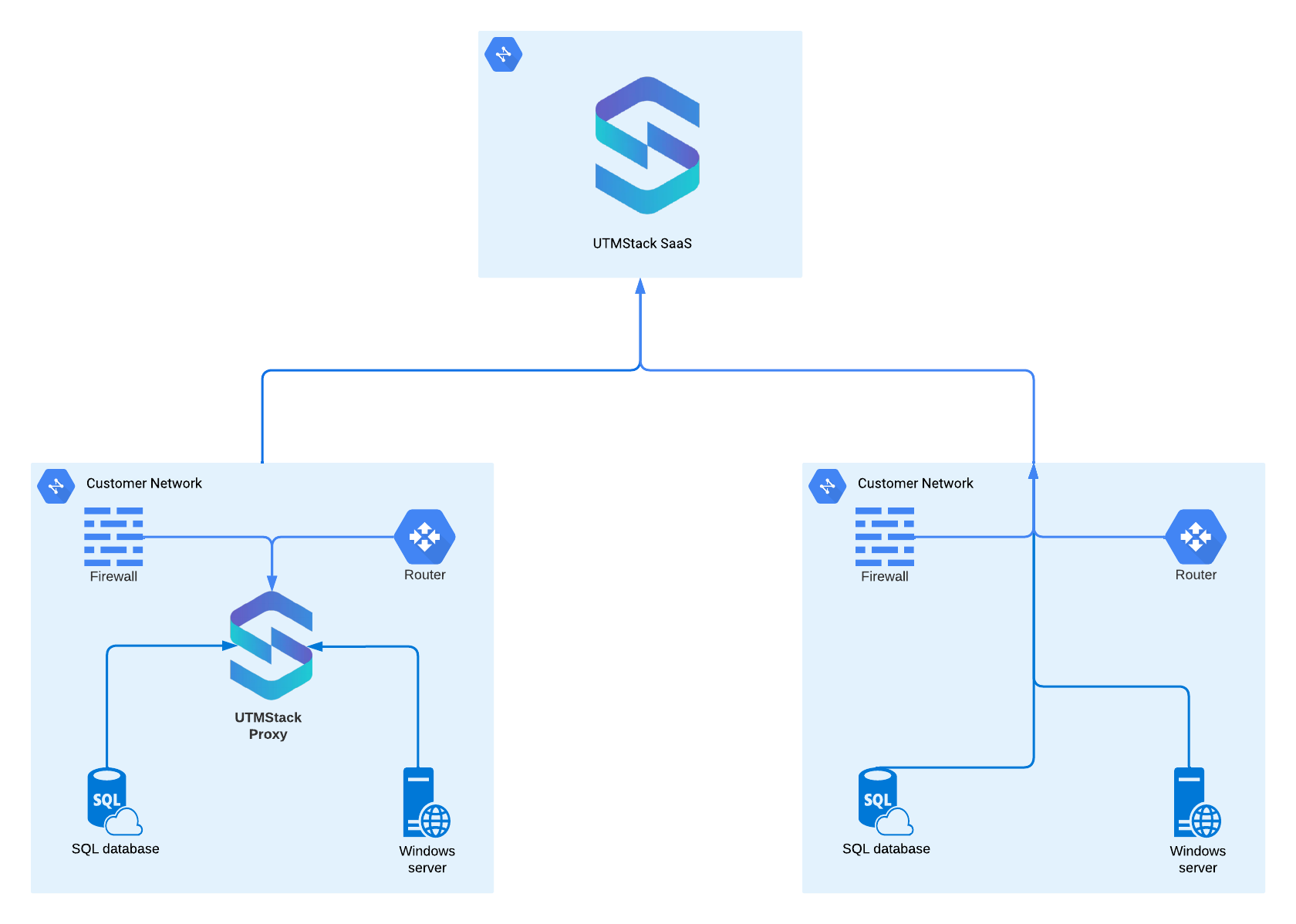
- Hosted and managed by UTMStack
- Automatic updates and scaling
- High availability included
- Professional support
- No infrastructure management
- Cloud-based deployment
- Agents or SyslogTLS for log collection
- Automatic backups
- 24/7 monitoring
- Managed updates and maintenance
- Focus on your business, not infrastructure
Data Flow Architecture
Processing Pipeline
- Data Collection: Agents, syslog, APIs collect logs from sources
- EventProcessor: Parses and normalizes incoming data
- Correlation Engine: Real-time correlation before storage
- Storage Layer: Elasticsearch for indexed log storage
- Alert Engine: Generates alerts based on correlation rules
- SOAR: Automated response workflows
- Query Engine: Fast search and analysis
- Web Interface: User interaction and visualization
Security Architecture
Encryption in Transit
- TLS 1.3 for all connections
- Certificate-based authentication
- Encrypted agent communication
Access Control
- Mandatory Multi-Factor Authentication
- Role-based access control (RBAC)
- Session management
- Audit logging
Data Isolation
- Container isolation
- Network segmentation
- Encrypted data at rest
- Secure credential storage
Service Security
- Microservices architecture
- Fail2ban protection
- Regular security updates
- Vulnerability scanning
Scalability Considerations
When to Scale Horizontally
Add Worker Nodes When
- Processing more than 500 data sources
- CPU usage consistently above 70%
- Log ingestion delays occur
- Real-time correlation lags
High Availability Options
For mission-critical deployments:- Database Clustering: Elasticsearch cluster for data redundancy
- Manager Redundancy: Active-passive manager configuration
- Worker Pools: Multiple workers ensure continued processing
- Load Balancing: Distribute user connections across manager nodes
- Backup Systems: Automated backup and disaster recovery
Network Architecture
Required Connectivity
Security Zones
- DMZ: Agent collectors and log receivers
- Internal: Core processing and storage
- Management: Web interface and administration
- Isolated: Customer data in federated deployments
Comparison: v10 vs v11 Architecture
| Feature | v10 | v11 |
|---|---|---|
| Processing Engine | Logstash | EventProcessor |
| Scalability | Vertical only | Horizontal + Vertical |
| Architecture | Monolithic | Distributed (Manager/Worker) |
| Plugin System | Integrated | Modular |
| Resource Usage | Higher | Significantly lower |
| MFA | Optional | Mandatory |
| Central Management | Limited | Full support |
| Auto Updates | Manual | Automatic (optional) |
Choosing Your Deployment Model
Single Node
Choose if:
- < 500 data sources
- Budget-conscious
- Simple management preferred
- Single location deployment
Multi-Node
Choose if:
-
500 data sources
- High performance required
- Large data volumes
- Enterprise scale
Federated
Choose if:
- MSP or MSSP
- Multiple customers
- Centralized monitoring needed
- SOC operations
SaaS
Choose if:
- No infrastructure team
- Prefer managed solution
- Quick deployment needed
- Focus on operations not maintenance
Next Steps
Installation Guide
Install UTMStack v11
System Requirements
Check detailed requirements
Firewall Configuration
Configure network access
SSL Certificate Management
SSL Certificate Management